This is a term paper submitted to “Musikkvitenskap mellomfag” at the University of Oslo, spring 2000.
Abstract
The paper starts with presenting some of the concepts behind digital audio compression, before describing some of the most popular sound formats available today: the different standards in the MPEG-family, RealAudio, ATRAC, MS Audio, SACD and DVD Audio. The author argues that there are lots of positive aspects of sound compression, but perhaps this overwhelming popularity will limit the development of new and better standards, like Super Audio CD or DVD Audio.
- Introduction
The last years have shown a growing amount of various multimedia standards and applications, like MP3, MPEG, MD, DVD, DAB, AC-3 and RealAudio. Similar for all of them is the dependency on sound compression during digital transfer, and they have all been applied to a wide range of applications (Brandenburg and MPEG-2 FAQ):
- Broadcasting: Digital Audio Broadcasting (DAB, ADR, Worldspace Radio, Cable Radio, Internet Radio), cable and satellite TV (DVB, USSB, DirecTV, EchoStar)
- Storage: Digital Video (DVB, video CD, DVD), Digital Compact Cassette (DCC), Solid State Storage Audio, Portable music devices (MP3-players)
- Multimedia: Computer based Multimedia (e.g. Java, Flash, games, consumer programs), multimedia on the Internet
- Telecommunication: ISDN transmission, contribution links, distribution links
All the big companies behind the different standards claim that their product provides the best HI-FI quality at the lowest bit rate. But how do these standards actually work and which one is better for what use?
I will start off by briefly describing some concepts of digital audio compression, and how insight into psychoacoustics can help produce transparent sound compression. I assume the reader to have basic knowledge of digital signal processing, and will therefore not define standard concepts. Then I present some of the most popular sound formats, both those intended mainly for Internet usage and those giving high quality sound. Finally, I will discuss how the enormous popularity of standards using sound compression might result in unconsciousness about sound quality, and how this can limit the development of better standards. It is then interesting to pose the question: is MP3 the friend of the youth or the enemy of the sound quality?
- Principles of Digital Audio Compression
With analog systems the different possibilities of audio quality was basically limited to choosing between stereo or mono, and the quality of the tape. Unlike the virtually “infinite” quality of analog systems, digital signals are dependent on the conflicting interests of high sampling rates versus small storing space. When Sony/Philips introduced the CD in 1980, they settled at a standard of 44,1 kHz and 16 bit. This confirms with the concept “Nyman frequency” telling us that the sampling frequency has to be minimum twice the highest frequency in the signal to avoid distortion (Jensenius, 1999). Since the human ear is capable of hearing sounds up to 20 kHz, the CD-medium should be able to present all frequencies audible to the human ear.
The audio on a CD is stored in a format called Pulse Code Modulation (PCM), where each sample is represented as an independent code (Pan, 1993). This requires a huge amount of samples to reproduce a good signal. We can easily calculate the amount of storage space necessary to save one minute of CD-quality sound, when we know that there are 44 100 samples every second, and that there are eight bits per byte:
44 100 samples/s * 2 channels * 2 bytes/sample * 60 s/min = 10 MB/min
If we were to have such audio files on the Internet, it would take up to an hour just to download one minute of high quality music, using a conventional modem. Clearly, it was necessary to develop systems to compress the sound while keeping up a high sound quality.
2.1 Lossless Coding
An ideal coding scheme allows for reconstruction of the original signal. One method of perceiving this is by dividing the signal up into 4 categories: irrelevant, redundant, relevant, and not redundant. The scheme will then remove either the amount of irrelevant or redundant information or both. This type of encoder can give a compression ratio of 1:2 up to 1:3,5, dependent on the signal, and still be able to fully reconstruct the original sound (Erne, 1998: 152). Different encoders use both linear prediction and a transformation with entropy encoding (for example Huffmann). The linear predictor minimises the variance of the difference in signals between samples. Then the entropy coder allocates codewords to the different samples (ib.), so that they can be reproduced in the correct order.
2.2 Psychoacoustics
During the years scientists have discovered a range of disabilities in the human ear. These prove extremely useful when compressing sound, as the whole idea of psychoacoustic models is to determine what parts of a sound are acoustically irrelevant.
An interesting result is that the sensitivity of the ear varies with frequency. The ear is most sensitive to frequencies in the neighbourhood of 4 kHz. Thus some sound pressure levels that can be detected at 4 kHz will not be heard at other frequencies. This also means that two tones of equal power but different frequency will probably not sound equally loud. Equi-loudness curves showing this effect is graphed in Figure 1a. The dashed curve indicates the minimum level at which the ear can detect a tone at a given frequency (Tsutsui, 1992). Filters based on this concept are used in most coding algorithms.
Another important concept is that of auditory noise masking. A perceptual weakness of the ear occurs whenever the presence of a strong audio signal makes a spectral neighbourhood of weaker audio signals imperceptible (Pan, 1993: 6). For a certain period of time only the strongest tonal signal may necessarily be presented, because the weaker signals will not be audible anyway. Look at the examples of simultaneous masking and temporal masking in Figure 1b and 1c. From these we can conclude that simultaneous masking is more effective when the frequency of the masked signal is equal to or higher than that of the masker. As well, forward masking can be effective for a longer time after the masker has stopped than the backwards masking. Both these concepts greatly help to compress the sound signal.
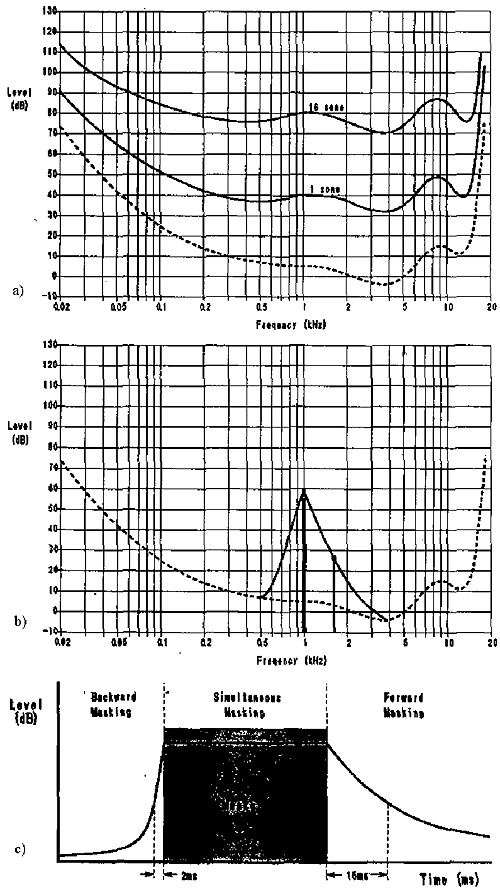 Figure 1: a) Equi-loudness curves b) Simultaneous masking curve c) Example of Temporal masking (Tsutsui 1992)
Figure 1: a) Equi-loudness curves b) Simultaneous masking curve c) Example of Temporal masking (Tsutsui 1992)
The concept of dividing the spectrum into critical bands, is explained by the ear’s tendency to analyse the audible frequency range using a set of subbands. These subbands can be thought of as the frequency scale used by the ear. The frequencies within a critical band are similar in terms of the ear’s perception, and will therefore be processed separately from sound in the other critical bands. As we see from Table 1, the critical bands are much wider for higher frequencies than for lower. This means that the ear receives more information from the low frequencies than from the higher (Tsutsui, 1992), and this should be thought of when deciding what parts to compress the most in a signal.
Table 1: Critical bands (Tsutsui, 1992)
Critical Band Frequency (Hz) Critical Band Frequency (Hz)
Low High Width Low 0 0 100 100 1 100 200 100 2 200 300 100 3 300 400 100 4 400 510 110 5 540 630 120 6 630 770 140 7 770 920 150 8 920 1080 160 9 1080 1270 190 10 1270 1480 210 11 1480 1720 240 12 1720 2000 280
There are several other topics of psychoacoustics that are used in sound compression algorithms, but those mentioned above are the most popular and the ones giving the best signal reduction. It is also important to remember that these concepts are based on the perception of people with “average ears”, and that some people, especially children, may be able to hear sounds in the regions being cut off.
- Different Sound Formats
There are lots of different sound formats available, some made for use on the Internet and others as pure high quality standards. I will go through some of the most widely spread formats and also some of the new rising standards that probably will dominate in the future.
3.1 MPEG-1
The Moving Pictures Experts Group (MPEG) was set up as a group under the International Organisation for Standardisation (ISO) in the end of the 1980s. It was meant to provide standards in sound and video compression, and how the two should be linked together. The audio part of MPEG-1 is described in three different layers of increasing complexity and performance. Layer I offering a compression ratio of 1:4, Layer II of 1:6 to 1:8 and finally the advanced Layer III of 1:10 to 1:12. These layers are hierarchically compatible, such that Layer III decoders can play all three layers, while Layer II decoders can play Layer I and Layer II bit streams. In the standardisation, MPEG has specified the bit stream format and the decoder for each layer, but not the encoder. This was done both to give some more freedom to the implementers, but also because some of the big companies taking part in the standard did not want to reveal their business concepts. Nevertheless, the MPEG-group has submitted some publicly available C source for explanation purposes.
An overview of the MPEG-1 audio encoding is shown in Figure 2. All three layers are built upon the same standard specification of perceptual noise shaping, using the same analysis filterbank. To ensure compatibility, all the compressed packets have the same structure with a header explaining the compression being used, followed by the sound signal. This proves practical because every sequence of audio frames can be used separately as they provide all the necessary information to decode it. Unfortunately, this also increases the file size, something the groupes behind competing standards have been criticising. Another common and important feature is the ability to insert program related information into the coded packets, such that items could be linked in for example multimedia applications (Fraunhofer, FAQ Layer 3).
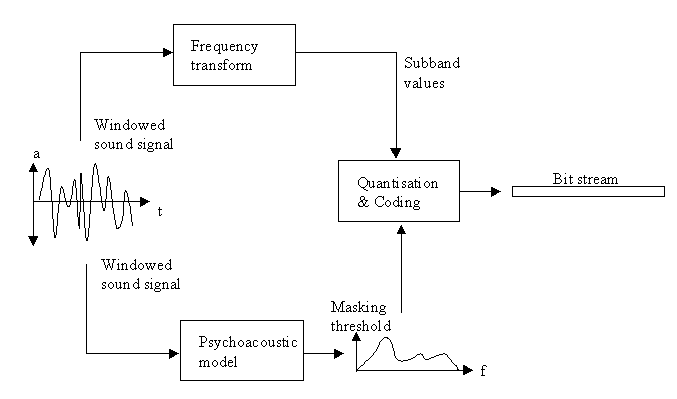 Figure 2: Model of MPEG-1 audio encoding (MPEG Audio FAQ).
Figure 2: Model of MPEG-1 audio encoding (MPEG Audio FAQ).
The three layers all have different applications, depending on the bit rate and compression ratio wanted. For example, Layer I was the audio standard in the Digital Compact Cassette (DCC) launched by Philips. Undoubtedly, the most popular of these have been Layer III, but then often called MP3. The name MP3 was invented when making file extensions on the Windows platform. Since the typical extension consists of three letters, “MPEG-1 Layer III” became MP3. This name has resulted in a lot of confusion, and lots of people mix up the different MPEG-standards and the corresponding layers. Note that there does not exist any MPEG-3 specification! As for the compression ratio, Table 2 shows some of the different qualities Layer III can deliver. The popular “MP3-music” on the Internet is most often coded with a bit rate of 128 kbit/s.
Enhancements of Layer III over Layer I and Layer II include nonuniform quantization, the usage of a bit reservoir, Huffmann entropy coding and noise allocation instead of bit allocation. These are all powerful tools, requiring much better encoders than the other layers. This is no problem today, as even the cheapest computer easily manages to process such files.
Table 2: Typical performance data of MPEG-1 Layer III (Fraunhofer, Layer 3):
Quality Bandwidth Mode Bit rate Comp. ratio
Telephone 2,5 kHz Mono 8 kbit/s 1:96 Shortwave 2,5 kHz Mono 16 kbit/s 1:48 AM radio 7,5 kHz Mono 32 kbit/s 1:24 FM radio 11 kHz Stereo 56-64 kbit/s 1:24-26 Near-CD 15 kHz Stereo 96 kbit/s 1:16 CD >15 kHz Stereo 112-128 kbit/s 1:12-14
3.2 MPEG-2
MPEG-2 BC became an official standard in 1995. Carrying the tag BC (Backward Compatible), it was never intended to replace the schemes presented in MPEG-1 but rather supply new features. It supports sampling frequencies from 16 kHz to 22,05 kHz and 24 kHz at bit rates from 32 to 256 kbit/s for Layer I, and from 8 to 160 kbit/s for Layer II and Layer III. For the coding process this only implies some more tables included to the MPEG-1 audio encoder.
Another important feature is the addition of multichannel sound. MPEG-1 only supports mono and stereo signals, but for coding movies it was necessary to design support for 5.1 surround sound. This includes five full bandwidth channels and one “low frequent enhancement” (LFE) channel operating from 8 kHz to 100 kHz (MPEG-2 FAQ). Because of the backwards compatibility it was necessary to present a solution where all six channels could be mixed down to a stereo signal. If we call the two stereo channels L and R, adding a matrix system to the sound solves this:
L: left signal + (a · centre signal) + (b · left surround signal)
R: right signal + (a · centre signal) + (b · right surround signal)
where a and b represent a specific codec. Hence a full stereo picture can be reproduced in the decoder. But this system was greatly criticised, among others by Roger Dressler the technical manager of Dolby Laboratories. He argued that MPEG-II surround sound was not fitted as a new consumer format, and that it was limited by the backward compatibility (Braathen, 96). Therefore MPEG started working on a new standard. This was originally thought to be MPEG-3, but since the video part of the new standard could easily be implemented in MPEG-2, the audio part was named MPEG-2 AAC. Issued in 1997 (MPEG-2 FAQ), this new standard features the Advanced Audio Coding (AAC), a totally different way of representing the sound than PCM. AAC defines a coding standard for 1 to 48 channels with sampling rates of 8 to 96 kHz, and three different profiles of various complexity (MPEG FAQ). Instead of the filter bank used by former standards, AAC uses a Modified Discrete Cosine Transform (MDCT). Using the concept of Temporal Noise Shaping, this shapes the distribution of quantization noise in time by prediction in the frequency domain (MPEG-2 FAQ). Together with an increased window length of 2048 instead of 1152 lines per transformation, this gives a compression approximately 30 % more efficient than that of MPEG-2 BC (Fraunhofer, AAC FAQ).
A big advantage of MPEG-2 AAC is that it was never designed to be backward compatible. This solved the MPEG-2 BC limitation problems when processing surround sound. As well, MPEG changed the highly criticised transport syntax, leaving to the encoding process to decide whether to send a separate header with all audio frames or not (MPEG-2 FAQ). The result is that AAC provides a much better compression ratio relative to former standards, and is appropriate in all situations in which backward compatibility is not required or can be accomplished with simulcast. Formal listening tests have shown that MPEG-2 AAC provides slightly better audio quality at 320 kbit/s than MPEG-2 BC can provide at 640 kbit/s (ib.). It is expected that more and more services will turn towards AAC as the sound compression system. With time it will probably be the successor of Layer III (MP3), featuring the same quality at 70% of the size at a rate of 128 kbit/s.
3.3 RealAudio G2
RealAudio 1.0 was introduced in 1995 as an Internet standard developed to offer fast downloads over conventional modems. Thus a lossless or transparent compression was wide ahead of the scope of the standard. The newest version in the standard is called RealAudio G2, featuring up to 80% better download times than its predecessors. This has made it the most popular tool for live broadcasting on the web.
One major improvement is the handling of data loss while streaming. The available bandwidth on the web may vary, and earlier this often resulted in “empty spaces” in the sound being played. The RealAudio G2 codec has been designed so that the data packets are built up by parts of neighbouring frames, overlapping each other so that one package may contain parts of several seconds of music. The result is that if some packets are “lost”, the possible gap will be filled in by an interpolation scheme. Even if several packets are lost, the engine will manage to produce a quite good result (RealNetworks). This works out in much the same way as interlaced GIF-pictures.
The RealAudio G2 codec is optimised for Internet speeds of 16 to 32 kbit/s, but with support for rates from 6 to 96 kbit/s. This has made it popular because it allows a wide range of bit rates, as well as the ability to constantly change bit rate while streaming. Due to its great success, RealNetworks has expanded the scope offering not only sound transfer, but also video and different multimedia platforms such as VRML and Flash. They also work on a descriptive tool to describe the content of the media being played, a “light version” of MPEG-7 as will be explained later. A problem with the RealNetworks products is the lack of public source and the great limitations in the free coding tools. The consumer market could easily turn down an expensive system, and even the big companies would rather think about using free and easily available tools as AAC or MS Audio instead (Weekly, 1999).
3.4 Microsoft Audio v4.0
As for everything else, Microsoft also wants to be in the game, and they have made their own standard called Microsoft Audio v4. They have been very strict on not publishing any information about how this standard is implemented, but they have revealed that it is not based on filterbanks. David Weekly has made an extensive test of MS Audio compared to RealAudio and MP3. He is quite impressed and argues that it may be as good as MPEG in the near-to high quality range. On the negative side is the fact that it only runs on computers with Microsoft platforms (Weekly, 1999).
3.5 Minidisc/ATRAC
Sony launched the Minidisc in 1992, but it was not until 1996 that the consumer market got interested. It was never meant to compete with the CD but rather to be a replacement of the cassette tape as an easy-to-use, recordable and portable device. The term Minidisc only refers to the medium, the square disc, while the coding system is called ATRAC (Adaptive Transform Acoustic Coding for Minidisc). Based on psychoacoustic principles, the coder divides the input signal into three subbands and then makes transformations into the frequency domain using a variable block length. The transform coefficients are grouped into nonuniform bands according to the human auditory system, and then quantized on the basis of dynamics and masking characteristics (Tsutsui, 1992). While keeping the original signal of 16 bit and 44,1 kHz, the final coded signal is compressed by approximately a ratio of 1:5. The last years this system has become very popular, especially some of the ultra portable players featuring long playback times and good recording possibilities.
3.6 MPEG-4
With this new standard MPEG wants to provide a universal framework integrating tools, profiles and levels. It does not only integrate bit stream syntax and compression algorithms, but offers a framework for synthesis, rendering, transport and integration of audio and video (Erne, 1998: 155).
The audio part is mainly based upon the standards outlined in MPEG-2 AAC. Perceptual Noise Substitution (PNS) is among the new tools, and it works to save transmission bandwidth for noise-like signals. Instead of coding these signals, the total noise-power together with a “noise-flag” is transmitted. In the decoder the noise is re-synthesised during the decoding process (ib.). Another important feature is the scalability, giving the encoder the possibility to adjust the bit rate according to the complexity of the signal (Thom 1999).
Interesting for many developers is the ability to synthesise sound based on structured descriptions. MPEG-4 does not standardise a synthesis method, but only the description of the synthesis, meaning that any known or unknown sound synthesis method can be described (MPEG-4 FAQ). Lots of sounds and music are already made through synthesis methods, and by using MPEG-4 the final audio conversion can be left for the end computer. A parallel to graphics is the ability to make vector-based pictures and animations.
Text To Speech Interfaces (TTSI) have been around since the advent of personal computers, but MPEG-4 will standardise a decoder capable of producing intelligible synthetic speech at bit rates from 200 bits/s to 1,2 kbit/s. It will be possible to apply information such as pitch contour, phoneme duration, language, dialect, age, gender and speech rate. According to reports, the sound sounds quite real and reliable and the system has enormous capabilities. One advantage is the sound synchronisation in animations. The lips of a person talking in an animation could easily be synchronised to her lips, so that they will correspond no matter which language or speed she is talking.
An MPEG-4 frame can be built up by totally separated elements. This means that everything from all visual elements in a video picture to every single instrument in the sound can be controlled individually. Just imagine that you have a five-channel recording of a quintet playing Beethoven. Then you can just turn off one of the instruments and play that part yourself. Or if you watch a movie, you may be able to choose which language every single actor should speak, or wear, or even do. The concept of hypertextuality really gets to its power, with almost unlimited possibilities.
3.7 MPEG-7
While the former MPEG standards are designated to represent the information itself, MPEG-7 will represent the information about the information. The standard will not involve any sound compression in itself. Neither is the standard implemented in any available applications as the working group has yet to publish something more than the Working draft of December1999. Basically, MPEG-7 is meant for describing the content of media, and officially it is called ”Multimedia Content Description Interface”. What is sure is that the standard will be built up by involving three different parts: Descriptors, Descriptor Schemes and a Description Definition Language (MPEG-7 FAQ). It evolves from a serious problem of today’s Internet; the lack of a logical description of media files. For example, MPEG-7 will allow people to hum some lines of a melody into a microphone connected to their computer, and then a list of matching sound files will be listed. Another example is if you are interested in music played by a specific instrument. Then you can search for sounds with similar sound characteristics. MPEG-7 also opens for Automatic Speech Recognition (ASR) so that you can make a search by just forming a phrase like: “Find me the part where Romeo says ‘It is the East and Juliet is the sun’” (MPEG-7 FAQ). All these examples show the highly relevant connection to MPEG-4, as MPEG-7 provides the tools for accessing all the content defined within an MPEG-4 frame.
3.8 DVD Audio
Some of the sound compressing systems are presented above, but there are also some formats striving to only give the best possible audio quality. One of them being DVD Audio, presented by the DVD Forum. Everything was ready for a launch on the mass market by the end of 1999, but with the cracking of the code system of DVD video, it has been postponed while working on a better security system.
A DVD Audio disc looks similar to a normal CD, but it is capable of delivering much better sound quality during the 74 minutes. It allows six different sampling rates: 44,1, 88,2, 176,4, 48, 96 and 192 kHz, with a resolution of either 16, 20 or 24 bit. While the two best samplingrates can only be applied to a stereo signal, the others can be used for 5.1 surround sound. Even though a DVD Audio disc has a storage capacity of up to 5 GB, the original signal takes even more space. To account for this, DVD Audio uses a type of lossless packing called Meridian Lossless Packing (MLP) applied to the PCM bit stream (Braathen, 1999).
Some of the biggest music production firms like Warner and Universal have announced their support for DVD Audio. They have also secured that they will include a layer with the sound compressed in Dolby AC-3 as this will only take up about 5% of the space on the disc. Then at least all the DVD video players being sold will be able to play the new discs with a limited quality. However, it seems unlikely that the discs will be compatible with normal CD-players all over the world.
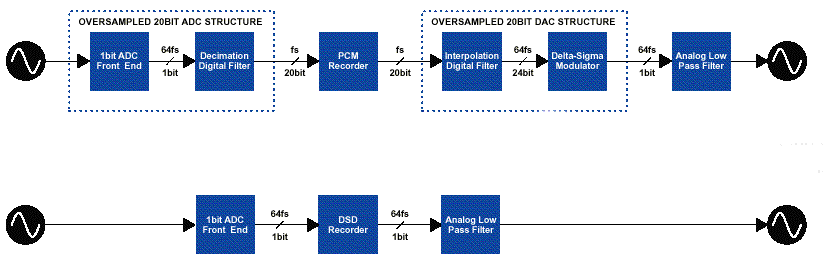
Figure 3: The conversion process for conventional PCM signals (top) and with the new DSD (bottom). Notice how this shortens the compression process (Braathen 1999).
3.9 SACD
A concurrent to DVD Audio is the Super Audio CD launched by Philips and Sony. Here the two firms have left the old PCM system and started out with a system called Direct Stream Digital (DSD). This means a totally different way of thinking about the encoder/decoder, using 1 bit converters through the whole process. Such converters have been used in consumer electronics for a while, but then it has been necessary to translate the PCM signal before using the 1 bit chips. As shown in Figure 3, the bit stream of the SACD system is recorded directly to the disc, without converting to PCM (Ruud, 2000). This requires a sampling rate of more than 2800 kHz, to ensure good quality. With a technique of noise shaping, the final signal will have a bandwidth of more than 100 kHz with a dynamic range of 120 dB. Since this technique is much more efficient than PCM, it will allow for up to 6 independent, full bandwidth channels with lossless packing (Braathen 1999).
An advantage of SACD is that the discs play with full quality in normal DVD players being sold today. As well, the discs are usually made of two transparent SACD layers and one core layer that can be read by normal CD players. This means that the SACD should ideally be compatible with all CD players around the world.
It is argued that the SACD is an attempt from Philips/Sony to get hold of a new patent, as the CD patent is running old these days. This surely would involve a lot in annual income for these companies, as the standard is not publicly available. Another argument is that it will be expensive to convert all studio and recording equipment to the new 1 bit technology. While lots of independent organisations and companies want the DVD Audio to become the new standard, it seems like we are going to get a public fight. Because as it is today, some SACD discs have just started to reach the market, while DVD Audio is still striving with their security system. What is sure is that both systems prove clearly superior to normal CDs, or as the test panel in a HI-FI magazine is saying: “CD-players costing six-digit numbers sounds comic when listening to what cheap players can do with 24/96 recordings” (Ruud, 1999).
- Discussion
Through the Internet, millions of people have the possibility to download music in fairly high quality to their computer. While young people convert their CD collection to MP3s and put on the net, the music companies are furious because they can do nothing but watch potential income pass back and forth on the web. Music licensing has become a big problem, as it is possible to make perfect digital copies, compress them and share them with the whole world. Still my concern is more on the sound quality side.
No doubt, there are lots of advantages of compressed music. If you have music files on your computer, the different decoder programs have advanced functions for creating playlists, presenting additional information about the song or performer or output visual presentations of the spectrum. Normal PCs often have hard disks of up to 20 GB. If filled up, this will give more than 300 hours of continuous music, without even worrying about changing a CD. Portable MP3-players let you copy files from your computer to a small device, and some companies have even launched MP3-players in conventional rack format. The minidisc has also become extremely popular, and especially the possibility to obtain good, digital recordings.
It is difficult to measure sound quality for compressed files. Old quality terms like signal-to-noise ratio are useless when for example a sound is stripped for certain frequencies. The only way to measure the quality has been through expensive listening tests. There have been carried out lots of big tests the last years, and most of them use a method called “triple stimulus, hidden reference”. Shortly, it applies a listening sequence ABC, where A is the original, and one of B and C is the original and the other being the coded sound. The listener has to evaluate both B and C using a scale from 1.0 to 5.0, where 5.0 means transparent sound quality. This method gives quite precise and statistically satisfactory results. The results are different, but many tests conclude that there are only minor differences between the original sound and the one compressed to for example an MP3 128 kbit/s signal.
However, these tests are carried out in professional studios under controlled conditions and using expensive studio monitors. The general MP3-listener is sitting with her computer playing sound through her mediocre PC sound card with a pair of standard PC-speakers. This involves a serious degrading of the final output sound quality. Firstly, there is the problem of the encoder. Lots of free, publicly available encoders let you produce your own files. But to ensure that the coding process is fast, most of them often skip some of the processes specified in the different standards. This is mostly a problem with encoders making MPEG files, since this standard is open. When it comes to the decoding, many of the most popular decoders, for example WinAmp, have obvious bugs, resulting in for example some specific frequencies being cut off, or unwanted masking effects.
Another problem is the hardware. All normal PC sound cards are capable of making sound, but they were never intended to play back high quality audio. The D/A chips on even the cheapest, standalone CD-player will most certainly outperform the chips placed on most sound cards. As well, the interior of a PC is not the ideal place for processing high quality audio, with lots of background noise from different devices like CD-ROM, hard drive, and especially the fan. The final, output sound may not only be encoded and decoded wrongly, but also distorted by noise and disturbances. Even if the speakers are of high quality, it cannot save a sound lacking stereo perspective, depth and overtones.
It is not my intention to withdraw people’s happiness of playing MP3-files on their computer, but rather make aware of some problems connected with compressing sound. The problem is not the different formats, because they are excellent for their use. But I think the whole society gets a problem when for example the biggest newspapers in Norway encourage people to convert the whole CD collection to MP3s. People will not only be used to an unnecessary degraded quality, but they may also limit the development of new and better standards. It is a fact that consumer interests often set the standard for future developments, and it is not guaranteed that the best alternative wins. An example of this was the battle between Beta and VHS on the home video scene. We could easily get a situation, where the advent of different sound compression systems, result in a glorification for smaller and more compressed sound files. That will be a serious loss for the high quality sound.
On the other side, some people have been arguing that the CD-medium lacks some of the richness and quality of the old LP. Hopefully that debate will finally come to an end with the introduction of SACD and DVD Audio. Both are capable of delivering a stunning sound quality of more than 24 bit and 96 kHz. This will hopefully thrill more than the music enthusiasts: “The music was not loud during the presentation, but gosh what a spacious playback: The music lived in the room as a breath of the summer winds, softly, light and tender. It played extraordinary easy, there were absolutely no sharp edges from the digital process.” (Ruud, 2000). Even though we might get a battle between these new “super standards”, tomorrows technology will probably be more than capable of playing both formats, as well as conventional DVD movies and CDs. The battle of the best sound is greatly dependent on the consumers, and hopefully they will claim their right for better quality.
- Conclusion
I have presented some of the various sound formats, intended both for use on the Internet and as a high quality medium. Certainly, sound compression for storage and transfer on the web is a great possibility offering loads of new and exciting features. Still, I think it should not be forgotten that the whole concept of sound compression is to remove something from the signal. Even though this might not seem to be audible by the human ear, it could have other effects degrading the total experience. A sound is more than just the tone you hear, it is a wave you can feel on your skin, just as the deepest bass tones. The removing of initially inaudible overtones may alter the overall richness and depth of the sound image in a room. It all melts down to the fact that acoustics is one of the oldest and still most difficult sciences. The conclusion of my topic question may be: yes, sound compression may be the friend of the youth and the whole society, but it is also the enemy of the sound! Therefore we should never take any chances, and rather be sure to choose the better quality if available. So take some time to put that old CD in your player and be confident that you get the best possible sound.
Bibliography
- Brandenburg, Karlheinz (1999): Mp3 and AAC explained, Proceedings of the AES 17^th^ International Conference on High Quality Audio Coding, Florence, Italy
- Braathen, Espen (1996): Den allsidige platen kommer!, article in Audio Video 1/96, http://home.sol.no/~espen-b/dvd/format.html
- Braathen, Espen (1999): Standardene for superlyd er klare!, http://home.sol.no/~espen-b/dvd/audio/index.html
- Casajús–Quirós, Francisco (1998): Digital Signal Processors for Real–Time Audio Processing, Proceedings of ‘98 Digital Audio Effects Workshop, Barcelona, Spain
- ISO/IEC 11172 (1993): MPEG-1 Coding of Moving Pictures and Associated Audio for Digital Storage Media at up to about 1,5 Mbit/s, International standard, http://drogo.cselt.stet.it/mpeg/standards/mpeg-1/mpeg-1.htm
- ISO/IEC DIS 13818 (1996): MPEG-2 Generic coding of moving pictures and associated audio information, http://drogo.cselt.stet.it/mpeg/standards/mpeg-2/mpeg-2.htm
- Erne, Marckus (1998): Digital Audio Compression Algorithms, Proceedings – 98 Digital Audio Effects Workshop, Barcelona 1998
- DVDNett: Neste generasjon CD: DVD Audio eller Super Audio CD?
- Fraunhofer Institut: Basics about MPEG Perceptual Audio Coding, http://www.iis.fhg.de/amm/techinf/basics.html
- Fraunhofer Institut: MPEG Audio Layer-3, http://www.iis.fhg.de/amm/techinf/layer3/index.html
- Fraunhofer Institut: MPEG-2 AAC, http://www.iis.fhg.de/amm/techinf/aac/index.html
- Fraunhofer Institut (1998): Frequently Asked Questions about MPEG Audio Layer-3, Version 3.0, March 1998, http://www.iis.fhg.de/amm/techinf/layer3/layer3faq/index.html
- Gayton, Cynthia (1999): Music Licensing Legal Developments for the Independent Label, http://ourworld.compuserve.com/homepages/Cynthia_Gayton
- Hacker, S. (2000): Mp3: The Definitive Guide
- Jensenius, Alexander Refsum (1999): Digitalisering av pianolyd, noen problemområder med vekt på fysisk signal og menneskelig oppfatning, term paper University of Oslo
- Koenen, Rob ed. (1999): Overview of the MPEG-4 Standard, http://drogo.cselt.stet.it/mpeg/standards/mpeg-4/mpeg-4.htm
- Martinez, Jose ed. (1999): Overview of the MPEG-7 Standard, http://drogo.cselt.stet.it/mpeg/standards/mpeg-7/mpeg-7.htm
- Meares, David, Watanabe, Kaoru and Scheirer, Eric (1998): Report on MPEG-2 AAC Stereo Verification Tests
- MPEG Audio FAQ: MPEG-1: Coded Storage of Sampled Sound Waves, http://www.tnt.uni-hannover.de/project/mpeg/audio/faq/mpeg1.html
- MPEG Audio FAQ: MPEG-2: Coded Transmission/Storage of Sampled Sound Waves, http://www.tnt.uni-hannover.de/project/mpeg/audio/faq/mpeg2.html
- MPEG Audio FAQ: MPEG-4 Audio: coding of natural and synthetic sound, http://www.tnt.uni-hannover.de/project/mpeg/audio/faq/mpeg4.html
- MPEG Audio FAQ: MPEG-7: Description of meta-information on sound, http://www.tnt.uni-hannover.de/project/mpeg/audio/faq/mpeg7.html
- MPEG (1998): MPEG-7 Context and Objectives, http://www.darmstadt.gmd.de/mobile/MPEG7/Documents/N2460.html
- Pan, Davis Yen (1993): Digital Audio Compression, article in Digital Technical Journal Vol. 5 No. 2, spring 1993
- Pan, Davis Yen (1995): A Tutorial on MPEG/Audio Compression. Article in IEEE Multimedia Journal Vol. 2, No. 7, 1995, pp. 60-74
- Russ, Martin (1996): Sound Synthesis and Sampling
- Ruud, Øyvind (2000): Den digitale lydfronten, article in Lyd & Bilde 4/2000
- Ruud, Øyvind (1999): Er CD-spilleren på vei ut?, article in Lyd & Bilde 11/1999
- Scheirer, Eric (1998): AudioBIFS: The MPEG–4 Standard for Effects Processing, Proceedings – 98 Digital Audio Effects Workshop, Barcelona 1998
- Serra, Xavier and Peeters, Geoffrey (1999): Audio Descriptors and Descriptor Schemes in the Context of MPEG–7, Proceedings of the 1999 International Computer Music Conference
- Signès, Julien (1999): Binary Format For Scene (BIFS): Combining MPEG-4 media to build rich multimedia services
- Thom, D., Purnhagen, H., Pfeiffer, S. (1999): MPEG Audio FAQ, Official FAQ from the International Organisation for Standardisation (ISO), http://www.tnt.uni-hannover.de/project/mpeg/audio/faq/
- Tsutsui, Kyoya and others (1992): ATRAC: Adaptive Transform Acoustic Coding for Minidisc, 93rd Audio Engineering Society Convention in San Francisco, 1992
- Väänänen, Riitta and Huopaniemi, Jyri (1999): Virtual Acoustics Rendering in MPEG–4 Multimedia Standard, Proceedings of the 1999 International Computer Music Conference
- Watkinson, John (1999): MPEG–2
- Weekly, David (1999): MSAudio vs MP3 vs RealAudio, http://www.mp3now.com/html/msaudiovsmp3.html
- White, Paul: Recording and Production Techniques for the recording musician
- Wright, Matthew (1999): Cross–Coding SDIF into MPEG–4 Structured Audio, Proceedings of the 1999 International Computer Music Conference